那个让Claude年收入破140亿美元的秘密,可能就藏在这27%里
你可能不知道,Claude去年收入已经悄悄突破了140亿美元。
更让你意外的是,这背后没有惊天动地的黑科技,没有"重新定义AI"的豪言壮语。一个分析师告诉我,他的团队用Claude做合同审查,效率提升了四倍;但同一个人也说,Claude在某些知识问答和推理速度上,其实不如GPT-5.4。奇怪的是,这并没有阻止大家用脚投票。
为什么?因为Claude解决了工作中最核心的问题——稳定、便宜、能跑通真实流程。
这个逻辑,最近在DeepSeek-V4身上再次得到验证。
那些年我们追过的模型,和踩过的坑
回忆一下你用大模型处理过长文档的场景。第一次,你扔给模型一份50页的招标文件,让它帮忙提取关键条款。模型回应很快,你心想这玩意儿真不错。结果到第200页时,它开始"失忆"了——忘了前面提过的资质要求,开始凭空编造不存在的评分标准。
这不是模型"不够智能",而是上下文变长后,计算和缓存成本失控了。就像一个人背着一整栋楼的资料去开会,每走一步都要承受重量,到后来连正常思考都做不了。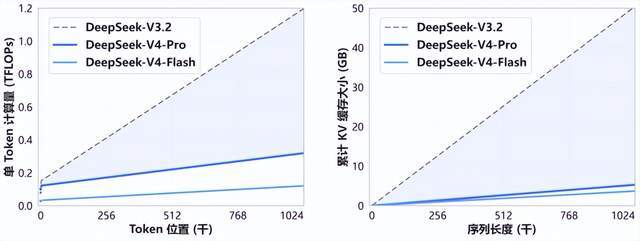
V4的27%和10%,针对的正是这个痛点。前者让生成每个token的计算量大幅下降,后者让"工作记忆"轻装上阵。换句话说,它不是让模型变得更聪明,而是让它在处理长任务时保持清醒。
一个真实的工作场景
我认识一个投资经理,他每天要处理几十份行业报告、几十条新闻线索、十几个项目的跟进记录。以前他的工作流程是:早起刷一遍新闻摘要工具,中午整理项目进展,傍晚写日报,周末复盘。时间被切割成碎片,深度思考的时间少得可怜。
后来他开始用AI工具辅助。他的Prompt很简单:每天新增哪些信息,哪些需要核实,哪些可以直接引用,导出格式是什么。但现实是,很多模型跑这个任务时,要么处理速度慢得离谱,要么上下文一长就"断片",要么价格高到算不起。
V4解决了这个问题。用他的话讲:"以前不敢让AI处理太多内容,怕它记不住、跑不动、算不起。现在这些问题都缓解了,我终于能把精力放在真正需要判断的事情上。"
DeepSeek的抉择与启示
V4选择了效率工程这条路,而不是追求"多模态""新物种"这类炫酷标签。这是一个有意思的信号。
它让我想到那些在各自领域做到极致的产品。它们不追求功能最多,不标榜技术最新,而是在某个核心场景做到了"不可替代"。Claude的成功不来自它比GPT更强,而来自它把"企业知识工作和代码工作流"这件事做透了。
DeepSeek现在面临的挑战也一样。V4证明了技术能力,但技术到商业之间还有产品、运营、生态这些硬仗要打。200亿美元估值需要模型转成稳定的商业系统,而不仅仅是跑分榜上的好成绩。
不过,有一点可以确定:那些真正改变工作效率的工具,从来不是因为它们"什么都能做",而是因为它们把"一件事做得很到位"。V4正在证明这一点。

